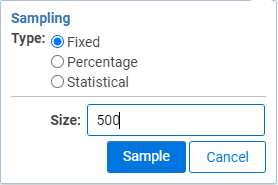
 The first step is to identify the documents you need to review. From that set, we are going to take a random sample of documents. We selected 500.
The first step is to identify the documents you need to review. From that set, we are going to take a random sample of documents. We selected 500.
Then we run the documents through eDiscovery AI.
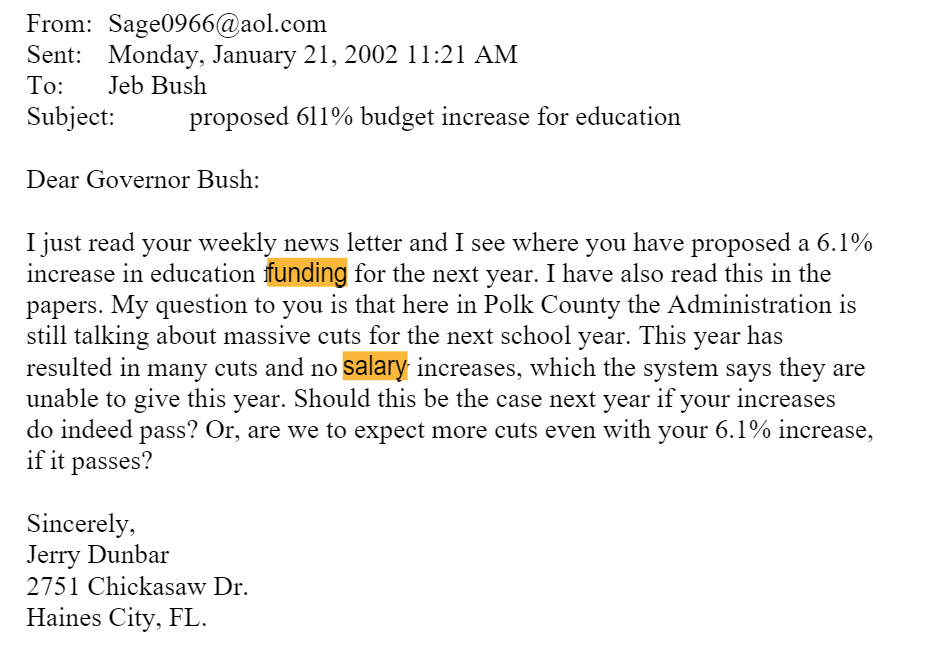
This is when we are presented with the opportunity to enter your instructions. Let’s come up with something pretty basic, but very broad:

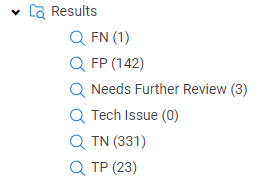
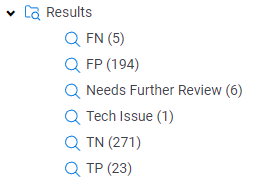 The results are in!
The results are in!
The first step is to folder up the True Positives, True Negatives, False Positives, and False Negatives. Remember, we have the TREC answer key to rely on so we don’t have to actually review the documents like you would in a real matter.
We can use these to calculate Recall and Precision for our first run.
Recall = TP/(TP+FN)
Recall = 23/(23+5)
Recall = 82%
Precision = TP/(TP+FP)
Precision = 23/(23+194)
Precision = 11%
The recall score is exactly where we need to be, but the precision definitely needs some work.
Now we want to take a quick look through the documents to see what we can improve.
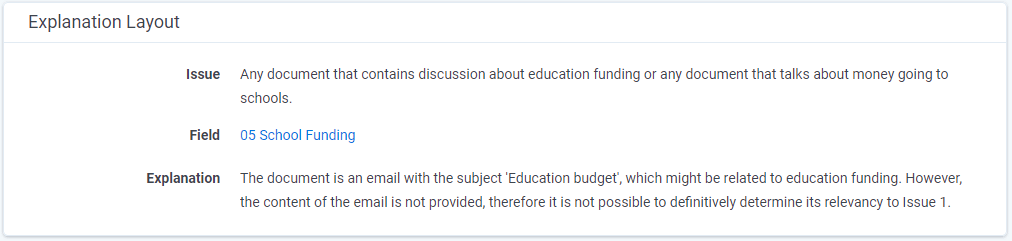
There is only 1 document that is a tech issue, and a quick review shows us that it exceeds the allowed file size limit.
![]()
While we could raise the file size limit and potentially review this document, we are going to leave it for now.






Then we take another random sample of 500 documents and we are off to the races!
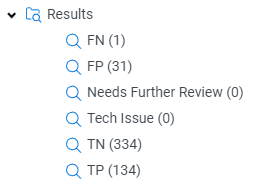
 The results are in!
The results are in!
The first step is to folder up the True Positives, True Negatives, False Positives, and False Negatives. Remember, we have the TREC answer key to rely on so we don’t have to actually review the documents like you would in a real matter.
The results already look much better.
However, we know many of the classifications on the answer key are not accurate, so we are going to take a look before we try to calculate our metrics.



 We can use these to calculate Recall and Precision for our first run.
We can use these to calculate Recall and Precision for our first run.
Recall = TP/(TP+FN)
Recall = 134/(134+1)
Recall = 99%
Precision = TP/(TP+FP)
Precision = 134/(134+31)
Precision = 81%
Now, we are at a point we are comfortable with our instructions.


