We all know AI technology is revolutionary, but is it defensible?
Even the best tool in the world would be worthless if it wasn’t allowed by the courts.
The good news is, we have been using machine learning for document review for the past 10 years, with thousands or even tens of thousands of example cases.
We just need to follow the standard process.
The general process for predictive coding has become pretty straightforward:
- Identify the review set
- Train the machine
- Run the documents through the classifier
- Evaluate the results
Believe it or not, it’s no different with AI.
Let’s get started!
Step 1: Identify the Review Set

We obviously need to know which documents need to be reviewed. That should be the easy part. Then we need to identify any documents that are bad candidates for review:
- Documents with no extracted text
- Audio files*
- Images*
- Extremely large files
For the most part, this has become an optional step. If you fail to pull out these types of documents, they are just going to get flagged as Needs Further Review, or Tech Issue, but it’s still a good process so let’s pull them out.
Note that I don’t mention anything about foreign language. AI doesn’t care what language the document is in, so they can all be reviewed together regardless of language.
When this step is complete, we should have one single folder of the documents that need to be reviewed.
*We have AI tools to review audio and images, but you need to run those separately because the process for instructions is a little different.
Step 2: Train the Machine

"Find all documents where any of our executives are discussing how to price widgets."
"Identify any documents where a discussion took place about the company's retirement plans"
"We are looking for any documents where an employee of Acme said something inappropriate to John Smith."
"Can you find any documents where someone makes a statement properly suggesting we should discriminate against people who support the Green Bay Packers."
For a more detailed analysis of how to craft proper instructions, see our latest blog titled “Crafting Instructions with eDiscovery AI.”
We might need to take 2 or 3 shots at coming up with the perfect instructions, but through some trial and error you’ll see it starts to come naturally.
Once you have your instructions, you can run them over all of your documents.
Step 3: Run Your Documents

Step 4: Evaluate Results

Everyone get out your calculators! And no spelling funny words upside-down.
Luckily, this is an open book test.
The goal of this step is to determine the quality of the classifications made by AI. So how do we do that?
First, we need an answer key. Something we can use to score the test. Without an answer key, we won’t know if the classification made by AI is right or wrong.
I have some bad news: You need to create the answer key!
We need to take a set of documents that we know are correctly classified, and compare them to the results of the AI classification. The only way to do that is with a control set using a subject matter expert.
So let’s do it! Find the set of documents that need to be reviewed from Step 1, and generate a random sample. We don’t need to get cute with stratified or fancy sampling. Just use whatever generic sampling tool is available in your review platform.
The size of the random sample is a hot topic.
In the early days of Predictive Coding, people were terrified of being challenged, so they took some extreme steps to ensure defensibility. Many would take random samples of nearly 10k documents!
Luckily, calmer heads have prevailed, and the suggested size has gone down considerably.
We still suggest people take a statistical sample rather than something fixed.
You can calculate sample sizes for your dataset here: https://www.calculator.net/sample-size-calculator.html
But to save you some work, here is all you need to know:
A sample with 95% confidence and 1% margin of error will return about 10,000 documents.
A sample with 95% confidence and 2% margin of error will return about 2,400 documents.
A sample with 95% confidence and 3% margin of error will return about 1,000 documents.
A long time ago, we used to recommend a 95/2 sample, but have found 95/3 to be sufficient for most cases.
So now we have our sample, and we have identified a subject matter expert to review it.
Time to get reviewing!
Have your subject matter expert look closely at every document in the random sample, and have them determine which are Relevant and Not Relevant. This is a very important job and the coding needs to be precise. If your answer key is all wrong, you are not going to have a good time.

This step isn’t complete until every document in your random sample has been classified as Relevant or Not Relevant.
Now we can grade the results!
While this could be it’s own blog, the quick and dirty is that we need to determine 2 things:
Recall: What percentage of all relevant documents were captured by our AI review.
Precision: What percentage of the documents deemed relevant by AI were actually relevant?
To do this, we use a confusion matrix. Don’t worry, the name is the most confusing part.
A quick guide on the confusion matrix:
True Positive = Instances where the AI classified the document as Relevant and the Subject Matter Expert also classified the document as Relevant.
True Negative = Instances where the AI classified the document as Not Relevant and the Subject Matter Expert also classified the document as Not Relevant.
False Positive = Instances where the AI classified the document as Relevant but the Subject Matter Expert classified the document as Not Relevant.
False Negative = Instances where the AI classified the document as Not Relevant but the Subject Matter Expert classified the document as Relevant.
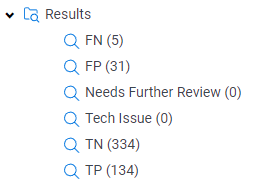
We can use these to calculate Recall and Precision for our first run. Let’s use these numbers as an example:
Recall = TP/(TP+FN)
Recall = 134/(134+5)
Recall = 96%
Precision = TP/(TP+FP)
Precision = 134/(134+31)
Precision = 81%
The Big Question:
Of course you want to know “What is an acceptable score” and of course the answer is going to be “It depends” because that’s the answer to everything.
The process is just as important as the score, so it is vital that you have a good subject matter expert and document every step of the process.
That being said, here my opinion and definitely not legal advice:
I would not consider recall below 70% to be defensible. The lowest score I would consider defensible in any situation is 70% recall and 50% precision.
A “good” score in my opinion would be 75-85% recall and 60+ precision. With those scores, I can sleep at night. There is no chance of being challenged on the score alone.
I’ve only seen recall above 90% with precision above 75% using traditional predictive coding one time ever, and the case was so straightforward it could have been done with keywords.
However, AI is playing on a different level. We are seeing 90%+ recall and 80%+ precision on every matter. It will be interesting to see if we start seeing people demanding higher scores. If you challenge 90% recall in court, you’re going to get your face on the cover of eDiscovery blogs. And not in a good way.
Conclusion
That’s it! With a good process on Step 2, you shouldn’t have any surprises and we can wrap this up with a nice little bow.
Be sure to review the documents that were excluded in Step 1, plus any Tech Issue or Needs Further Review documents.


