


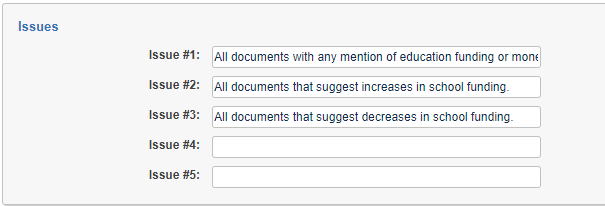

First, we need an answer key. Something we can use to score the test. Without an answer key, we won’t know if the classification made by AI is right or wrong.
I have some bad news: You need to create the answer key!
We need to take a set of documents that we know are correctly classified, and compare them to the results of the AI classification. The only way to do that is with a control set using a subject matter expert.
So let’s do it! Find the set of documents that need to be reviewed from Step 1, and generate a random sample. We don’t need to get cute with stratified or fancy sampling. Just use whatever generic sampling tool is available in your review platform.


We can use these to calculate Recall and Precision for our first run. Let’s use these numbers as an example:
Recall = TP/(TP+FN)
Recall = 134/(134+5)
Recall = 96%
Precision = TP/(TP+FP)
Precision = 134/(134+31)
Precision = 81%


